
Select from 90+ open-source applications
Get any stack you want running in minutes, and never think about upgrades again.

A unified analytics engine for large-scale data processing.
Available providers






Plural helps you deploy and manage the lifecycle of open-source applications on Kubernetes. Our platform combines the scalability and observability benefits of managed SaaS with the data security, governance, and compliance benefits of self-hosting Spark.
If you need more than just Spark, look for other cloud-native and open-source tools in our marketplace of curated applications to leapfrog complex deployments and get started quickly.
plural bundle install spark spark-aws
plural build
plural deploy --commit "deploying spark"
We make it easy to securely deploy and manage open-source applications in your cloud.
Get any stack you want running in minutes, and never think about upgrades again.
You control everything. No need to share your cloud account, keys, or data.
Built on Kubernetes and using standard infrastructure as code with Terraform and Helm.
Interactive runbooks, dashboards, and Kubernetes api visualizers give an easy-to-use toolset to manage application operations.
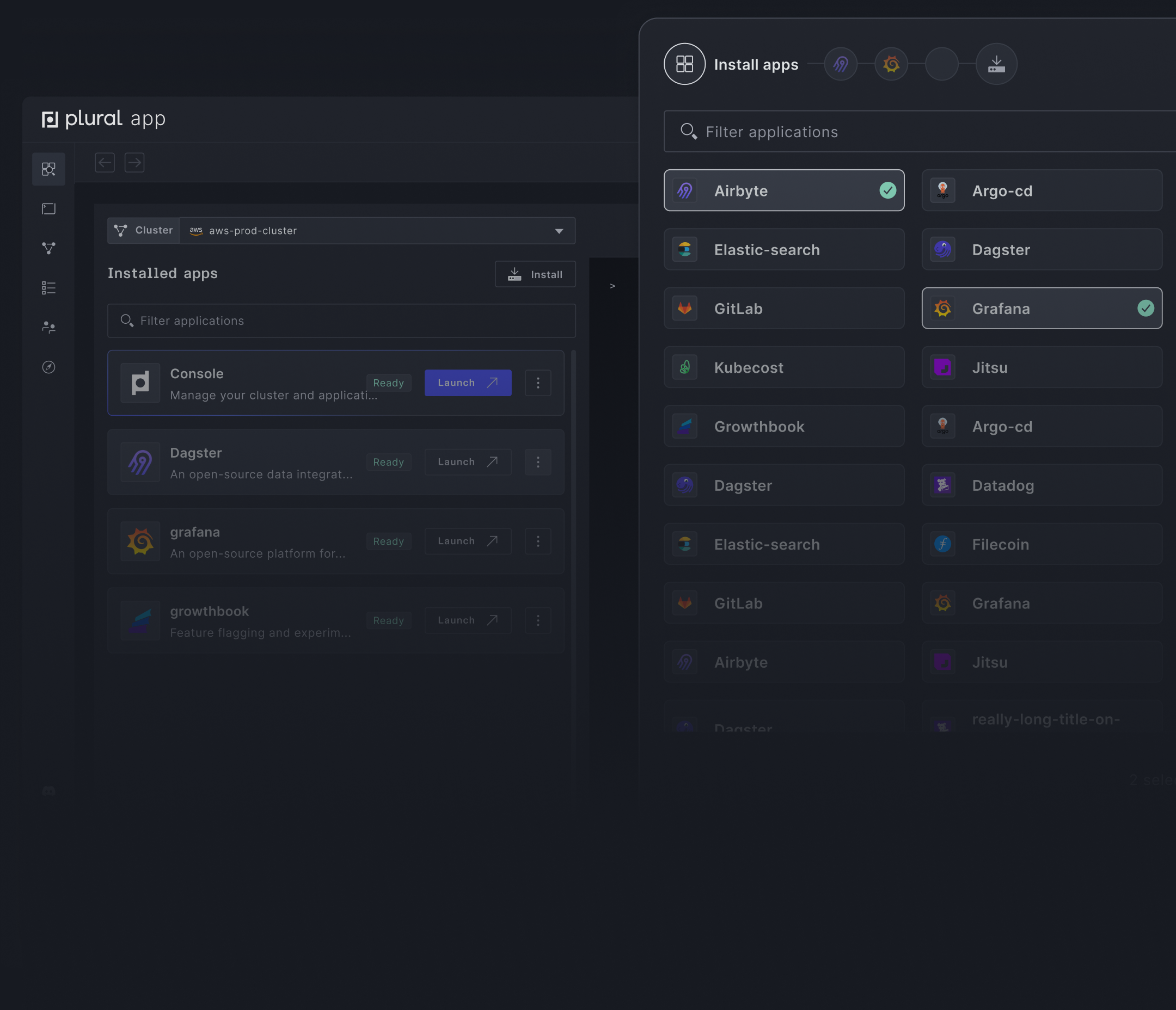
Build your custom stack with over 90+ apps in the Plural Marketplace.
We no longer needed a dedicated DevOps team; instead, we actively participated in the industrialization and deployment of our applications through Plural. Additionally, it allowed us to quickly gain proficiency in Terraform and Helm.
I have neither the patience nor the talent for DevOps/SysAdmin work, and yet I've deployed four enterprise-caliber open-source apps on Kubernetes... since 9am today. Bonkers.
This is awesome. You saved me hours of further DevOps work for our v1 release. Just to say, I really love Plural.
Wow! First of all I want to say thank you for creating Plural! It solves a lot of problems coming from a non-DevOps background. You guys are amazing!
We have been using Plural for complex Kubernetes deployments of Kubeflow and are excited with the possibilities it provides in making our workflows simpler and more efficient.
Plural has been awesome, it’s super fast and intuitive to get going and there is zero-to-no overhead of the app management.
Fnatic is a leading global esports performance brand headquartered in London, focused on leveling up gamers. At the core of Fnatic’s success is its best-in-class data team. The Fnatic data team relies on third-party applications to serve different business functions with every member of the organization utilizing data daily. While having access to an abundance of data is great, it opens up a degree of complexity when it comes to answering critical business questions and in-game analytics for gaming members.
To answer these questions, the data team began constructing a data stack to solve these use cases. Since the team at Fnatic are big fans of open-source they elected to build their stack with popular open-source technologies.











