
Where ArgoCd Falls Short (And What We Are Doing To Fix It)
ArgoCD is great but larger organizations face a few hiccups when using it. Here's what we are doing to solve them
Operationalizing Argo CD in a large organization has some hiccups and it’s worth diving into detail why those problems exist in the first place and how they are typically handled. By no means are we saying that Argo CD is a bad tool.
If you are deploying a simple application on Kubernetes and your use case is not complex, Argo CD works fine. After all, it is the market leader for continuous deployment tooling in the Kubernetes ecosystem, and it provides developers with a robust GitOps workflow and a UI to provide visibility into your applications and their current state.
Throughout this post, we’ll highlight how Argo’s architecture works under the hood, the tradeoffs of the two main models of utilizing Argo CD at scale, and what we are doing to fix this problem for the Kubernetes community.
Argo’s Architecture
ArgoCD follows the GitOps pattern of using Git repositories as the source of truth for defining the desired application state. ArgoCD is implemented as a Kubernetes controller and continuously monitors running applications and compares the current, live state against the desired target state that is specified in the Git repo.
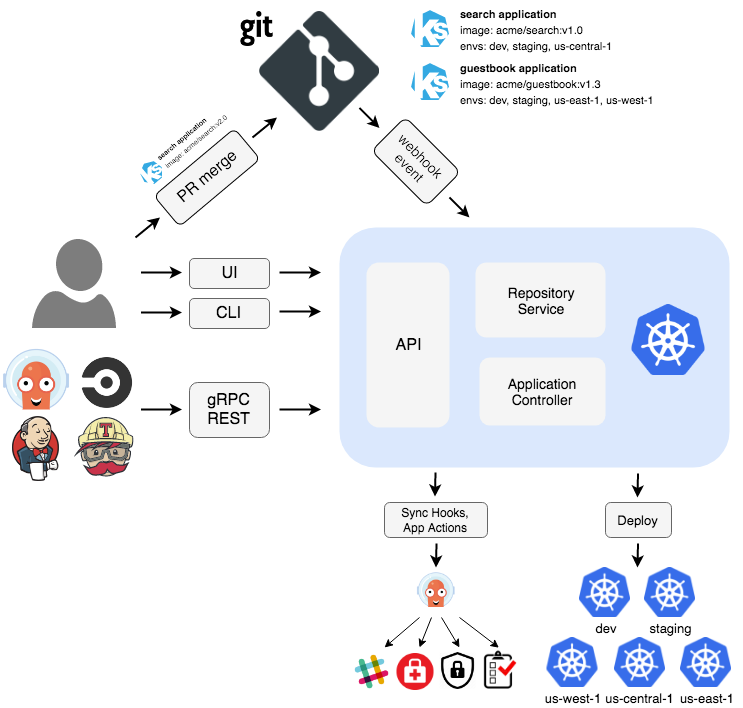
Argo is packaged as a Kubernetes operator with some additional gRPC services and a Redis cluster. The operator manages the lifecycle of its two custom resources; Application and ApplicationSet, and as a result can handle a lot of work.
In particular, this can involve applying hundreds or even thousands of Kubernetes resources, and also setting up Kubernetes watch streams to check the changes of all of them to report status. At scale, this is an incredibly network-intensive process, and the operator model requires leader election. This happens because the set of Kubernetes resources overwhelms the ability of a control loop to process.
The Downfall of ArgoCD
The tradeoffs this architecture creates have led to two main models of utilizing ArgoCD at scale:
- Sharded Multi-Cluster (Push Model): With this approach, you accept the scalability challenge and solve it by manually sharding your application controller. However, this approach also presents a few security challenges because the single multi-cluster Argo controller needs to be able to reach all workload-bearing clusters, which requires accepting Kubernetes credentials and opening network access to those clusters. If you do follow this approach your ArgoCD cluster becomes a golden opportunity for hackers to attack. With that said, you do gain some operational wins by only needing to manage a single Argo cluster, and also you maintain the visibility gained by the Argo UI.
- Single-Tenant Argo (Pull model): This approach applies deploying an instance of ArgoCD into each tenant cluster, and configuring each individually with the necessary Git credentials to sync the applications it will ultimately need. Frequently, this is coupled with an App-of-Apps model where you define a single ArgoCD application for all the apps for that cluster to make it easier to operationalize in Git. The biggest and most obvious drawback of this is you completely lose access to the Argo UI as a single dashboard for your application estate, which is likely a major reason it was chosen over alternatives in the first place. While this approach is more scalable, it does come with an operational burden as you’re suddenly tasked with operating as many Argo instances as Kubernetes clusters, each of which can be scaled poorly or fail for any number of reasons.
Finally, another common challenge organizations face with Argo is creating a staged release pipeline. Argo is ultimately built around a model of rapidly syncing a single cluster with a Git repository, but a large organization doesn’t truly deploy code in that manner. A common procedure is more along the lines of a merge to master bakes an image, and then that image proceeds through a sequence of clusters until it ultimately reaches a customer-facing production cluster.
Each step along the way should have automation to confirm the health of that code alongside other in-flight services that it likely depends on and are released according to their cadence, via integration testing, querying monitors, or any other means.
How Plural will fix this
After exploring existing solutions in the ecosystem, we have decided to develop our own continuous deployment solution. Specifically, we have successfully addressed the scalability and visibility challenges that often arise with ArgoCD. Moreover, we have prioritized the integration of pipelining as a core component of our Plural platform. This achievement was made possible through several significant modifications.
- The system is built with two tiers from the start, a control plane layer, and a sync agent. The control plane has horizontally scalable Git caching, a secret management system, and a Kubernetes Auth proxy to maintain visibility into clusters.
- The agent is a very thin manifest applier meant to be operationally painless. It establishes a GRPC channel to the control plane to allow Kubernetes API requests to flow through to clusters without having them be directly networkable. By doing so the control plane becomes a single pane of glass view of your entire Kubernetes fleet without compromising the security posture you would ideally want and still being infinitely scalable.
- The configuration system allows for a mechanism to build pipelines against, as configuration can flow from one service to another in an organized manner, and the deploy agent can receive jobs to perform tasks like integration tests and other necessary promotion gates.
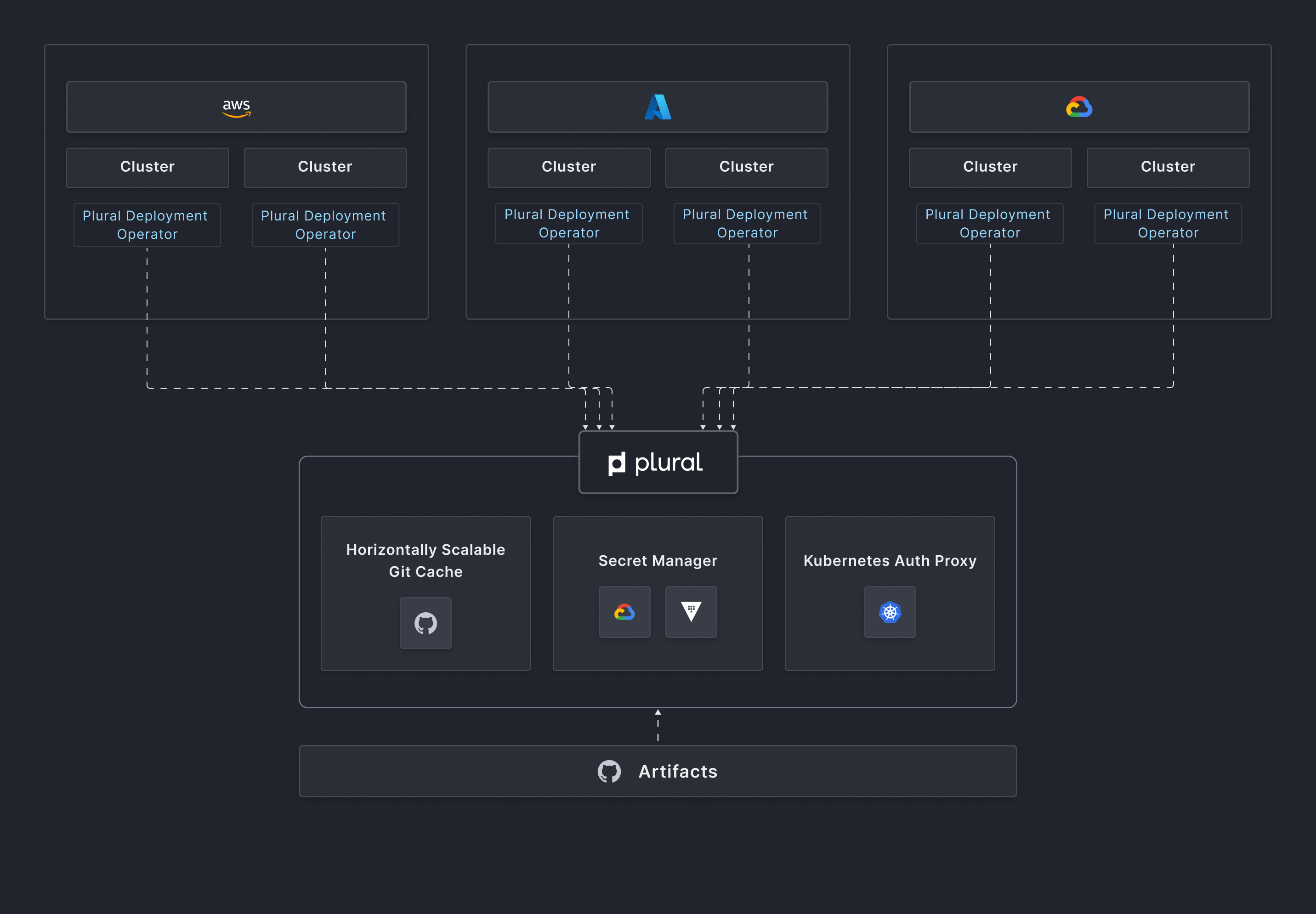
All of this is packaged and presented as a set of GraphQL APIs that can be integrated with infrastructure as code tooling like terraform, or called directly using your automation.
To learn more about Plural and our self-hosted Kubernetes fleet management platform, sign up for a custom demo below.

Newsletter
Join the newsletter to receive the latest updates in your inbox.





){kind=link}