
Bringing a good OSS experience to Kubernetes DevOps
Deploying and managing open source applications is tedious and time-consuming. It doesn’t have to be this challenging to get going on Kubernetes.
Table of Contents
This blog post was originally featured on the CNCF blog.
Open-source is at a crossroads at the moment. 97% of data stacks contain open-source code. However, deploying and managing open source applications is tedious and time-consuming.
Take an open source product like Apache Airflow for example. The popular workflow management system has over 26k stars on Github and is used by over 14k companies. Currently, the consensus among developers is to deploy their own Airflow instance themselves on Kubernetes.
Sounds simple, right?
Configuring and managing Airflow on Kubernetes can be difficult, especially if you are short on engineering resources or have never deployed Airflow itself on Kubernetes. Airflow itself is a complicated stateful application that is made of a SQL database and a Redis cache. Each of these components is technically difficult, and companies that ultimately end up using Airflow usually dedicate an engineer’s job to efficiently scale Airflow while ensuring it is always up and running.
It doesn’t have to be this challenging to get going with open-source applications on Kubernetes.
In this post, we’ll discuss:
- Why use Kubernetes to deploy your data stack?
- Three constraints organizations face when deploying open-source applications on Kubernetes
- Solving the three DevOps constraints
Why Use Kubernetes to Deploy Your Data Stack?

Over the past few years, I have seen a dramatic increase in companies opting to deploy their data stacks with Kubernetes. Throughout my engineering career, which includes tours at Amazon and Facebook, a lot of what I did was scale open-source applications in a completely self-managed way.
Obviously, at these organizations, we had access to greater engineering resources which allowed us to shift this process completely in-house. We didn’t need to use a managed service in the cloud, or a cloud offering from a software vendor to scale out open-source applications.
When I was first introduced to Kubernetes, it became pretty obvious to me it had the potential to automate a lot of the knowledge we had in-house at these organizations and deliver those benefits to the wider engineering community.
While I could go on and on regarding the benefits of using Kubernetes to deploy your data stack, I do think it’s important to highlight the three main benefits I have seen from customers that run their data stack on Kubernetes.
- Cost savings: In my opinion, the biggest benefit is the cost that organizations save, especially when they begin to mature as a business. Larger organizations that are running infrastructure at scale can realistically reduce their cloud bill by upwards of a million dollars per year. I have also seen incredible cost savings, especially when paired against the managed serviced layer. Buying a managed service solution often comes with a 40 percent markup to compute. With large-scale batch processing jobs, that cost adds up quickly.
- Simpler security model: Everything is a hardened network, with no worries about privacy and compliance issues. Being able to have strong compliance and privacy around product analytic suites is especially helpful when companies begin to talk about GDPR and CCPA environments that are challenging to enforce across the board at scale.
- Operationally simpler to scale out to multiple solutions: In most cases, developers likely have to run multiple technologies to solve their use case. For something like a data stack you can consider Airbyte with other solutions such as Superset, Airflow, and Presto. But that is challenging and time-consuming to do effectively. If they are committed to running all those applications together, a self-hosted Kubernetes model becomes quite powerful because it unifies all applications in a singular environment. Developers can create a unified management experience with a web UI on top. The other benefit is the application upgrade process is unified. The complexity involved with upgrading a tool like Kubeflow requires a lot of dependencies at the Kubernetes level. Those dependencies might clash with your deployment of an application like Airflow, which requires something similar to K9 or Istio under the hood. With a unified platform, this process is simplified, developers can easily run a diff check between the dependencies of all the applications and validate that they will be upgradable at any given time.
Three Constraints Organizations Face When Deploying Open-Source Applications on Kubernetes

Prior to founding Plural, I began to investigate the Kubernetes deployments of popular open-source applications. During my research, It became clear that there was a wide gap between a solid Kubernetes deployment and a fully hosted offering from either a cloud provider or a legacy software vendor. So, while Kubernetes has a lot of technical potential there is still a huge gap that is not generally commercially viable to the average developer.
After talking with hundreds of developers over the last two years, I have seen these three common constraints among organizations looking to deploy open-source applications on Kubernetes.
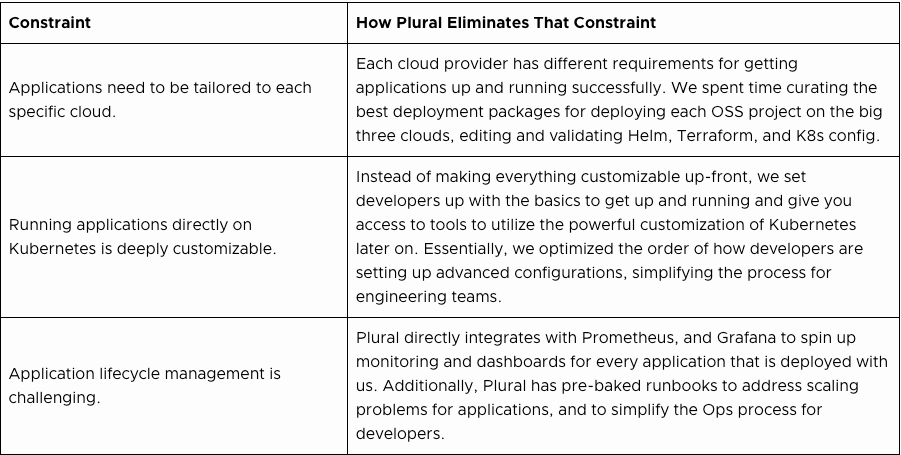
- Applications need to be tailored to each specific cloud. It has become pretty clear to me that solving for cloud customizability is as complex as a code management problem. Each cloud has its own services, APIs, and conventions which leads to developers navigating multiple sets of documentation depending on the cloud provider.
- Running applications directly on Kubernetes is deeply customizable. This usually impedes a functionable out-of-the-box experience, which most legacy tools and cloud providers are unable to accomplish. And solving a complicated problem like this in-house is a hassle, especially if you are already short on engineering resources.
- Application lifecycle management is challenging. Similar to solving for cloud customizability, application lifecycle management is an extremely complex process. In my experience, I have found that some applications are easy to install but a pain to manage, which leads to technical debt.
Currently, legacy constraints prevent all the major cloud providers (Amazon, Google, Microsoft) from doing this right since they need to protect their core cloud business. The core technology needed to solve this is there but is not readily available and offered in a holistic manner to the open market.
Solving the three DevOps constraints
While the constraints I just mentioned can be solved with enough DevOps firepower, they can present genuine roadblocks to teams without the specialized experience required to run OSS applications on Kubernetes. With our open source project, Plural, we have specifically solved each of these constraints.
Plural is a free, open-source, unified application deployment platform that dramatically simplifies running open-source applications on Kubernetes. Plural aims to make applications production-ready from day 0 and offers over 60 packages ready to deploy from our marketplace, allowing you to truly build the open-source stack of your choice.
With Plural, you also can:
- Install pre-packaged open-source applications with one command
- Add authentication/SSO to your open-source apps
- Deploy and manage deployments of Kubernetes with minimal prior experience
- Utilize a GitOps workflow with a batteries-included transparent secret encryption
If you are interested in learning more about Plural, everything we built is open-source, so feel free to check it out on our GitHub. If there is an open-source application you want available on the Plural marketplace, we encourage you to contribute it to the Plural ecosystem by following our documentation which outlines how to do so. Most of all, we are dedicated to making Kubernetes infrastructure easy to deploy for everyone by fostering a community of self-hosted engineers powered by open source.

Newsletter
Be the first to know when we drop something new.






{kind=link}