
Why Is Kubernetes Adoption So Hard?
Kubernetes is great, but engineering teams often struggle with adopting it at scale. Here are three challenges team face and how we plan on solving them for the Kubernetes community
Table of Contents
At Plural, we are huge fans of the Kubernetes ecosystem, and our team has years of experience working with it. Over the last two years, we have built an open-source product that allows users to deploy and manage open-source software seamlessly on Kubernetes.
However, during the last few months, we have seen a mixture of genuine fear and PTSD whenever Kubernetes is discussed. In an attempt to better understand why this is the case, we've interviewed dozens of engineering leaders to get their thoughts on where the Kubernetes ecosystem is lacking.
In particular, we’ve seen three primary points of friction in the adoption of Kubernetes:
- Provisioning and managing Kubernetes clusters through their lifecycle is difficult and grows in complexity as you scale. The biggest pain point seems to be managing Kubernetes upgrades, with API version deprecations or other small behavioral changes causing outages or lost engineering cycles.
- Maintaining a Kubernetes YAML codebase is error-prone and frequently untestable.
- Existing deployment tooling is powerful, but lacks critical enterprise-grade features. Tools do not integrate well with each other and still require manual integration with the rest of the Kubernetes stack.
Let’s further dive into these three challenges and how we plan on solving them for the Kubernetes community.
Kubernetes Provisioning is Hard
Even in a world with services like EKS, GKE, and AKS providing “fully” managed Kubernetes clusters, maintaining a self-service Kubernetes provisioning system is still challenging.
Toolchains like Terraform and Pulumi can create a small cluster fleet but don’t provide a repeatable API to provision Kubernetes at scale and can often cascade disruptive updates with minor changes not caught in review.
Additionally, the upgrade flow around Kubernetes is fraught with dragons, in particular:
- Most control planes require a full cluster restart to apply a new Kubernetes version to each worker node, which is a delicate process that can bork a cluster.
- Deprecated API versions can cause significant downtime, even a sitewide outage at Reddit.
Even if a version upgrade doesn’t cause unavailability, slight behavioral differences in Kubernetes APIs can cause wasted effort. We recently noticed the bump to Kubernetes 1.24 caused service account default secrets to no longer be present, which made that version incompatible with other Kubernetes terraform provider versions. While it was ultimately not enough to cause an outage, it was a huge waste of our time finding the root cause of the issue.
This is the modal case of issues with Kubernetes upgrades, but there’s still a very fat tail of bad outcomes like those described above. It also highlights the disconnected nature of the tooling ecosystem and how minor changes can cascade unpredictably throughout.
Kubernetes Codebases are Thorny
Kubernetes specifies a rich, extensive REST API for all its functionality, often declared using YAML. While it is relatively user-friendly, larger application codebases interacting with that YAML spec can frequently balloon into thousands of lines of code.
There have been numerous attempts to moderate this bloat, using templating with tools like Helm or overlays with Kustomize. We believe all of these have significant drawbacks, which impair an organization's ability to adopt Kubernetes, in particular:
- No ability to reuse code naturally (there is no package manager for YAML)
- No ability to test your YAML codebases locally or in CI (preventing common engineering practices for quickly detecting regressions)
Common software engineering patterns, like crafting internal SDKs or “shifting left,” (I hate the buzzword, but it’s important) are impossible with YAML as your standard. The net effect is going to be more bugs reaching clusters, slower developer ramp times, and just general grumbling throughout an engineering organization from clunky codebases.
A better development substrate is ultimately the solution, ideally one that uses a proper, typed programming language.
Deployment Pipelines on Kubernetes are Poorly Supported
Kubernetes has a rich ecosystem of CD tooling, with the likes of Flux and ArgoCD, but most are built primarily for simple single-cluster deployment use cases out of a unique git repository. To use any of them, you still need lower-level Kubernetes management expertise to provision and administer the cluster to which they deploy.
In particular, we’ve noticed Kubernetes novices are quite intimidated by all the details of authenticating to the Kubernetes API, especially when using managed Kubernetes that goes through about three layers of Kubeconfig → IAM authenticator → bearer token auth + TLS at the control plane.
In order to get a CD system working, you’ll need to be capable enough to deploy something like Argo-CD to fully manage the Kubernetes auth layer to get the systems integrated and hardened. While this is not an insuperable task, it is probably enough friction to make people reconsider using an inferior tool like ECS for their containerized workloads.
And even if you get all that set up, you still need to be able to create a staged deployment pipeline from dev → staging → prod to allow for appropriate integration testing of your code before exposing it to users. That often requires hand-rolling a tedious, complex git-based release process and is manual enough that you can’t self-serviceably expose it to other teams.
In an ideal state, the creation of these two things is seamless:
- The ability to rapidly create staged deployments, from dev → staging → production with little to no effort.
- Integration with a Kubernetes provisioning system, so you don’t have to manage the complexities of the Kubernetes auth chain to start deploying code and there aren’t toolchain incompatibilities arising from a duct-tape riddled homegrown solve.
A Better World
We think all of this can be solved in a single integrated solution, and are actively working on it as the next phase of the evolution of Plural. In particular, we’re going to connect these three main components:
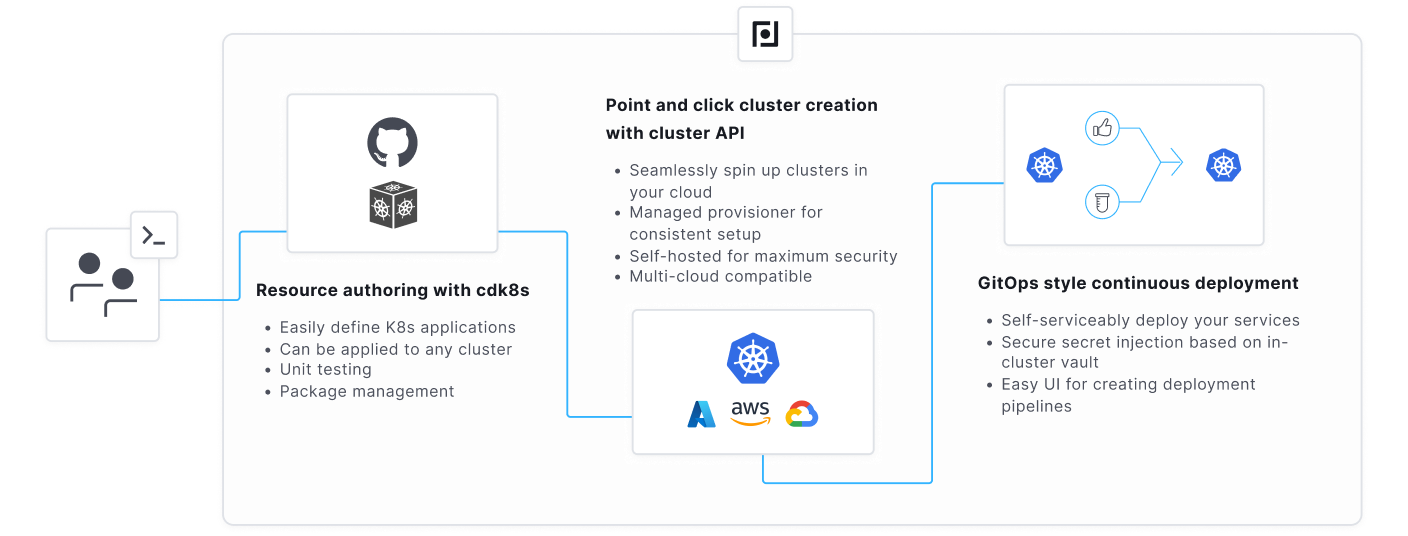
Manage Kubernetes At Scale with Cluster API
The emerging solution to managing cluster provisioning is using Cluster API (CAPI). CAPI provides a dynamic API that enables you to fluidly scale your Kubernetes usage for use cases like testing infrastructure or rapidly onboarding a new team. It also provides a robust reconciliation loop to handle complex Kubernetes upgrades in a fault-tolerant way that neither Terraform nor Pulumi’s CLI-based, remote-state-driven toolchain is purpose-built to handle.
It also allows us to consolidate the Kubernetes auth layer into a single master system, which will allow us to tie in deployment infrastructure and run scans to check for deprecated k8s API versions in a control plane to sanity test upgrades.
In more advanced use cases, you can use the standardized api to easily provision ephemeral environments for testing, or single tenant environments for customers that need data isolation.
Healthier Kubernetes Development with cdk8s
We’ve decided to provide first-order support for cdk8s to solve the issue of maintaining k8s code bases in a way that makes sense for developers. cdk8s allows you to author Kubernetes resources in common programming languages like Javascript, Golang, or Python.
This allows you to strap your Kubernetes code to any existing CI solution you might have and provide a robust testing ecosystem around your k8s code before releasing it into running clusters. Additionally, you can seamlessly reuse code using the language’s package management tooling, e.g. npm for Javascript or PIP for Python, allowing organizations to create proper, tested SDKs for service definitions or other resources that are commonly provisioned in Kubernetes.
We’ll also leverage the Plural community to build an ecosystem of starter packages to allow one-command setup for common frameworks like expressjs, Django, Rails, Spring Boot, and more. This will let you get started with your Kubernetes infrastructure without having to deeply familiarize yourself with the Kubernetes API and still have a robust, testable, reusable development workflow.
cdk8s is not directly integrated into a lot of common k8s deployment tooling like Argo and Flux, so we’ll take on the challenge of integrating them and making them available to the wider community.
Staged Releases with Pipelined Deployments
We intend to combine the CAPI-powered Kubernetes management infrastructure defining your Kubernetes fleet with tooling built on top of cdk8s to allow for a seamless, self-serviceable platform for managing complex Kubernetes deployment pipelines. It will provide powerful features like manual, automatic, or test-driven promotions, deployment windows, and more.
The flexibility of the infrastructure will allow us to provide more plastic deployment constructs like PR-based environments, or a self-serviceable development portal to allow teams to easily spin up new services with effectively one click.
The workflow will be entirely API-driven, so you’ll be able to integrate Plural CD with any existing CI solution like GitHub Actions, Jenkins, or CircleCI with off-the-shell tooling or the Plural CLI, and it’ll be self-hosted in your infrastructure so there’s no need to worry about exposing your cloud infrastructure to a potentially compromised third party.
Join us
These are our thoughts on how to make the Kubernetes ecosystem better. They come from battle-worn experience having deployed something like 350+ clusters for users of our platform.
Kubernetes is not as intimidating as people make it out to be. There should be a world where it’s effectively a replaceable appliance that can be slotted wherever you need it in your infrastructure. However, we do recognize we don’t live in that world and want to help get us there.
For a limited time, you can gain beta access to our latest product, Plural Continuous Deployment, an end-to-end solution for managing Kubernetes clusters and application deployment.
If we’re missing some obvious pain points, or if our ideas on how to solve them seem lacking in some way, please let us know. We appreciate any feedback.

Newsletter
Be the first to know when we drop something new.






{kind=link}